Trong kỷ nguyên số, chúng ta đang chứng kiến sự bùng nổ mạnh mẽ của các mô hình trí tuệ nhân tạo (AI). Tuy nhiên, đi kèm với sự phát triển vượt bậc này là một vấn đề ngày càng nổi cộm: tên gọi của các mô hình AI đang trở nên cực kỳ phức tạp. Đây là một mê cung gồm các từ viết tắt và biệt ngữ kỹ thuật khiến ngay cả những người dùng AI nhiệt huyết cũng phải bối rối. Sự rắc rối này không chỉ cản trở khả năng tiếp cận của người dùng phổ thông mà còn tạo ra rào cản đáng kể trong việc tìm hiểu và khai thác tối đa tiềm năng của những công cụ mạnh mẽ này.
Nhu cầu về một danh pháp đơn giản, thân thiện hơn cho mô hình AI
Dù mỗi mô hình AI mới ra đời đều mang tính đổi mới, nhưng tên gọi khó hiểu của chúng đang là rào cản nghiêm trọng đối với người dùng khi cố gắng tìm hiểu và phân biệt giữa các mô hình.
Tên gọi phức tạp: Rào cản lớn với người dùng phổ thông
Hãy xem xét ví dụ khi gã khổng lồ công nghệ Trung Quốc Alibaba ra mắt mô hình Qwen2.5-Coder-32B của họ. Ai thực sự hiểu được nó có thể làm gì chỉ qua cái tên này? Người dùng buộc phải tìm hiểu sâu vào các thuật ngữ chuyên ngành để nắm bắt.
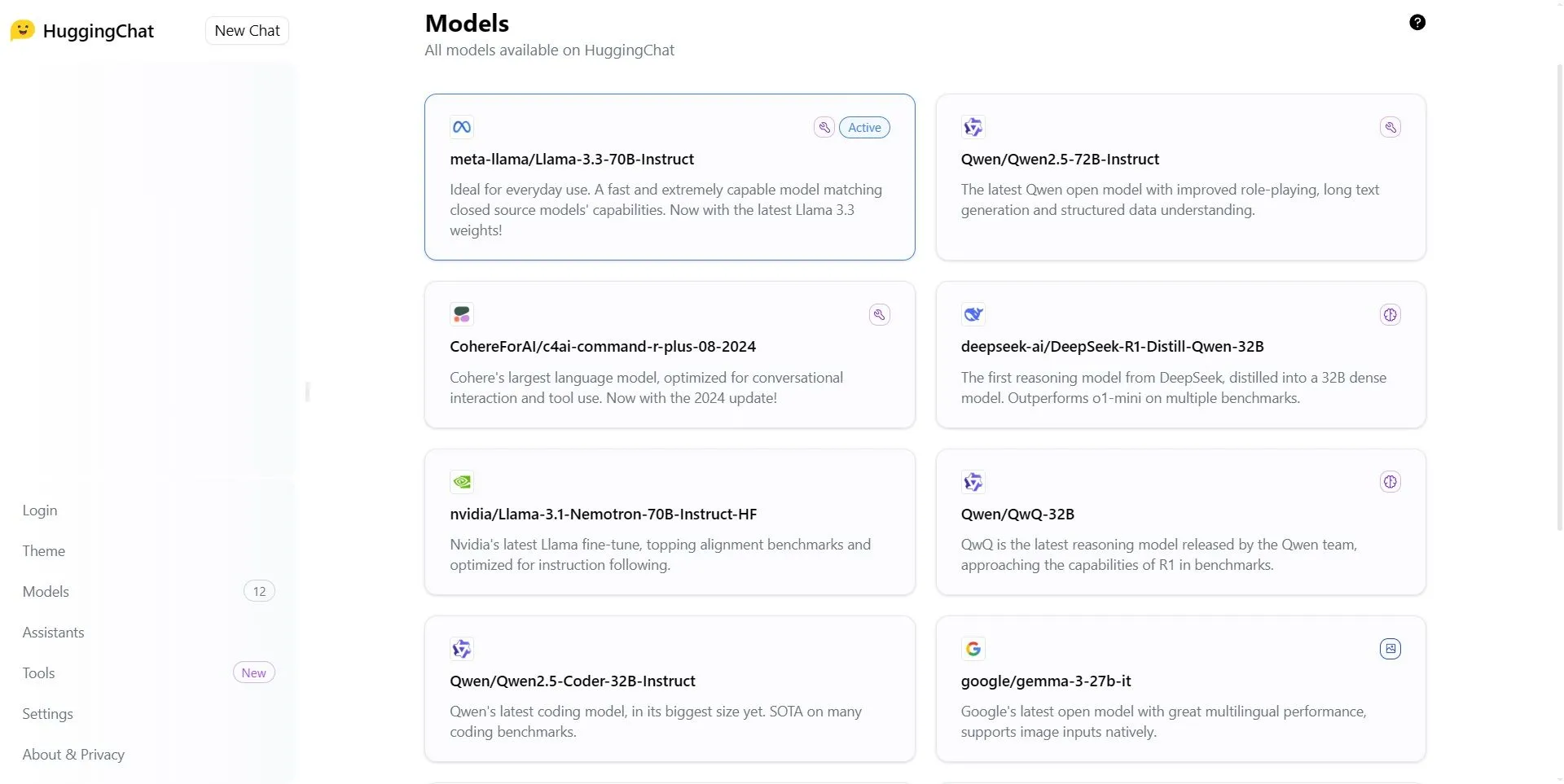 Giao diện Hugging Chat hiển thị danh sách tên gọi phức tạp của các mô hình AI/LLM
Giao diện Hugging Chat hiển thị danh sách tên gọi phức tạp của các mô hình AI/LLM
Trong khi các công ty AI thường chọn một tên sản phẩm sáng tạo như Gemini, Mistral hay Llama, thì tên cuối cùng của một mô hình lại thường bao gồm các thuộc tính kỹ thuật nhất định. Điều này có thể là số phiên bản hoặc lần lặp, kiến trúc hoặc loại mô hình, số lượng tham số, và các đặc điểm cụ thể khác. Ví dụ, tên Llama 2 70B-chat cho chúng ta biết rằng mô hình này của Meta (Llama) là một mô hình ngôn ngữ lớn (LLM) với 70 tỷ tham số (70B) và được thiết kế đặc biệt cho mục đích hội thoại (-chat).
Về bản chất, tên của một mô hình AI đóng vai trò như một cách viết tắt cho các thuộc tính chính của nó, giúp các nhà nghiên cứu và người dùng kỹ thuật nhanh chóng hiểu được bản chất và mục đích của nó. Tuy nhiên, đối với người dùng phổ thông, đây gần như là một mớ hỗn độn.
Hãy tưởng tượng một kịch bản khi người dùng muốn chọn giữa các mô hình mới nhất cho một tác vụ cụ thể. Họ phải đối mặt với các lựa chọn như “Gemini 2.0 Flash Thinking Experimental”, “DeepSeek R1 Distill Qwen 14B”, “Phi-3 Medium 14B” và “GPT-4o”. Nếu không đi sâu vào các thông số kỹ thuật, việc phân biệt giữa các mô hình này trở nên cực kỳ khó khăn.
Một loạt tên mô hình, mỗi cái lại khó hiểu hơn cái trước, càng làm nổi bật nhu cầu về một sự thay đổi cơ bản trong cách chúng ta đặt tên và trình bày các mô hình AI. Tên của một mô hình AI lý tưởng nên là một đại diện đơn giản, rõ ràng và dễ nhớ về mục đích và khả năng của nó.
Tầm quan trọng của cách đặt tên lấy người dùng làm trung tâm
Hãy hình dung nếu xe ô tô được đặt tên theo thông số động cơ và loại hệ thống treo thay vì những cái tên đơn giản, dễ gợi cảm xúc như “Mustang” hay “Civic”. Các quy ước đặt tên hiện tại cho các mô hình AI thường ưu tiên thông số kỹ thuật hơn là sự thân thiện với người dùng. Và trong khi một số thuật ngữ là cần thiết cho các nhà nghiên cứu, chúng gần như vô nghĩa đối với người dùng phổ thông. Ngành công nghiệp cần áp dụng một cách tiếp cận lấy người dùng làm trung tâm hơn đối với danh pháp. Các tên gọi đơn giản, trực quan và có tính mô tả có thể nâng cao đáng kể trải nghiệm người dùng.
Khám phá khả năng của mô hình AI: Cần cách tiếp cận dễ dàng hơn
Ngoài những cái tên khó hiểu, việc tìm hiểu xem một mô hình AI cụ thể thực sự có thể làm gì là một trở ngại lớn khác. Thông thường, các khả năng này bị chôn vùi sâu trong tài liệu kỹ thuật. Tình trạng này càng phức tạp hơn do sự đa dạng và các chức năng chuyên biệt của các mô hình AI. Chỉ một cái tên đơn giản có thể không truyền tải được toàn bộ khả năng của một mô hình AI.
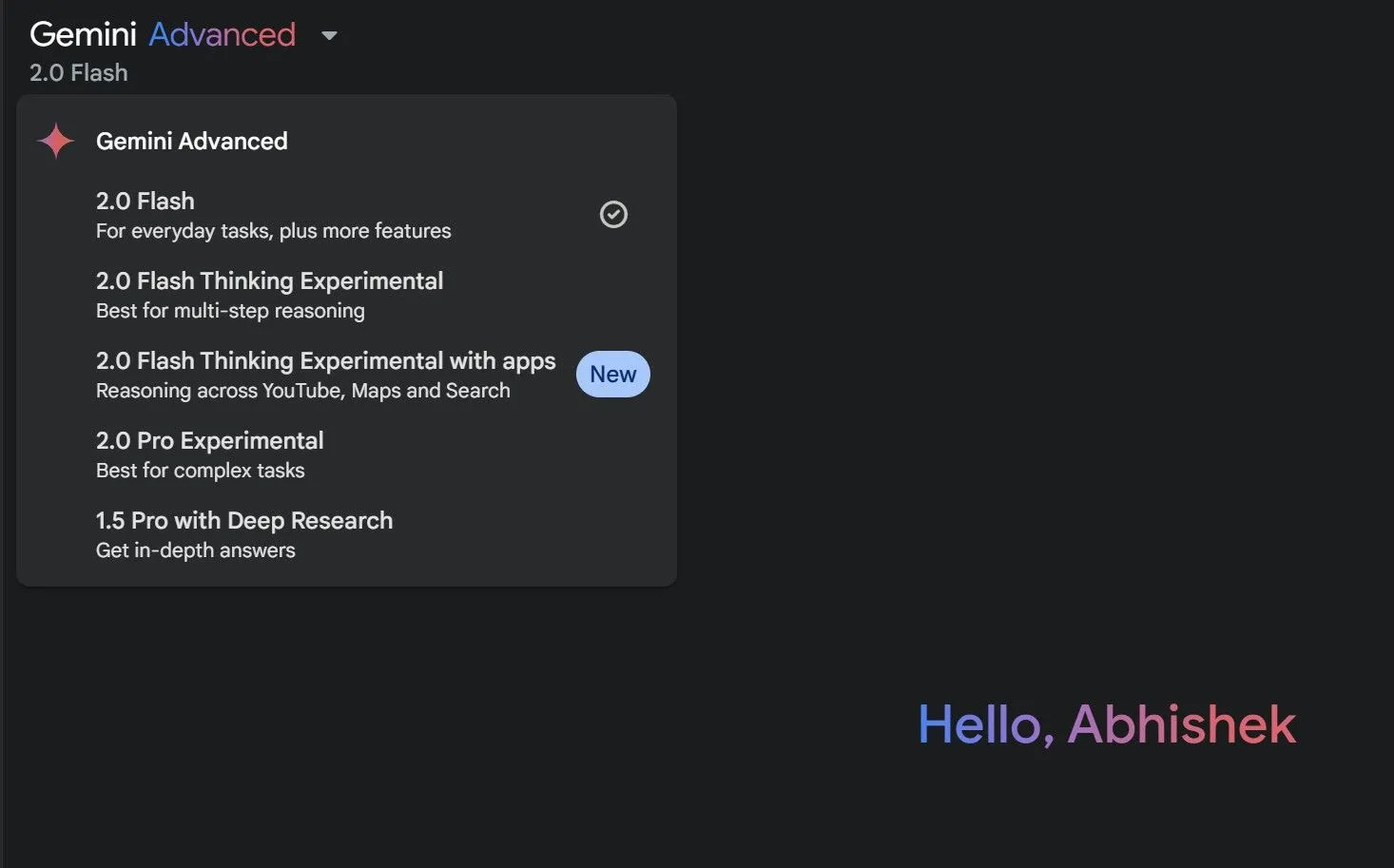 Mô tả các phiên bản mô hình AI Google Gemini giúp người dùng lựa chọn
Mô tả các phiên bản mô hình AI Google Gemini giúp người dùng lựa chọn
May mắn thay, các công cụ AI tận dụng những mô hình này thường bổ sung một mô tả nhỏ để chỉ rõ trường hợp sử dụng hoặc khả năng của chúng. Ví dụ, Google đã chỉ rõ rằng mô hình Gemini 2.0 Flash Thinking sử dụng khả năng suy luận nâng cao, trong khi 2.0 Pro là tốt nhất cho các tác vụ phức tạp. Mặc dù chưa lý tưởng, nhưng đây là một sự hỗ trợ nhất định.
Thay vì dựa vào các thuật ngữ kỹ thuật, tên mô hình nên phản ánh chức năng hoặc khả năng chính của chúng. Nếu cần các từ viết tắt, chúng nên được chọn cẩn thận để đảm bảo dễ nhớ và dễ phát âm. Ngoài ra, nên sử dụng các số phiên bản rõ ràng và súc tích để chỉ ra các bản cập nhật và cải tiến.
Hơn nữa, các mô hình AI có thể được phân loại với các tên gọi truyền tải chức năng chính hoặc tính năng độc đáo của chúng, chẳng hạn như “Bot hội thoại”, “Tóm tắt văn bản” hoặc “Nhận diện hình ảnh”. Sự rõ ràng như vậy sẽ giúp phi bí hóa công nghệ AI. Cách tiếp cận này sẽ hợp lý hóa quá trình khám phá, cho phép người dùng nhanh chóng xác định các mô hình và công cụ AI phù hợp nhất cho các tác vụ của mình mà không cần phải sàng lọc qua một mê cung các tên và mô tả khó hiểu. Tuy nhiên, cần lưu ý rằng hầu hết các mô hình ngôn ngữ lớn (LLM) có khả năng đa dạng và có thể thực hiện nhiều hơn một tác vụ. Vì vậy, cách tiếp cận này có thể không lý tưởng cho các mô hình ngôn ngữ lớn tiên tiến.
Tình trạng hiện tại của tên gọi mô hình AI có thể gây khó hiểu. Một sự chuyển đổi sang danh pháp đơn giản hơn và các phương pháp khám phá được cải thiện có thể nâng cao đáng kể trải nghiệm người dùng và giúp công nghệ tiên tiến này dễ tiếp cận hơn với mọi người. Cho đến lúc đó, việc cập nhật thông tin, tận dụng các tài nguyên cộng đồng và thử nghiệm với các mô hình khác nhau có thể giúp người dùng điều hướng thế giới AI phức tạp. Bạn có nghĩ rằng cách đặt tên mô hình AI nên đơn giản hơn không? Hãy chia sẻ suy nghĩ của bạn trong phần bình luận nhé!